Thank You Google: How to mine Bitcoin on Google’s BigQuery
Harnessing the power of SQL to mine cryptocurrency in the cloud
I love Google BigQuery. It’s a managed, highly scalable data platform, which means you can query enormous amounts of data very quickly (e.g. 4 Terabytes in less than 30 secs!). I regularly use it my projects (like the Spanish Lesson Action for the Google Assistant), and I’m always amazed by the high performance.
Last week, we organized a Dev.IL Meetup about the Blockchain, the technology behind Bitcoin, and I was struck by one of the talks from Asaf Nadler, explaining the mechanisms behind the technology that makes Bitcoin tick (feel free to watch the talk here, but fair warning, it’s in Hebrew :-). When I went home after the meetup, I had my BigQuery console open with some analytics query I wrote the day before, and I got this idea: What if I could use BigQuery for mining Bitcoin? Is it even possible? Can this be cost-effective? Given the impressive scalability of BigQuery, it seemed it could be a good match.
(Spoiler: it was! Up to 25 Giga-hashes/second, free, and very fun! Read on to find out how…)

I was very intrigued, and so I decided to give it a try. I had been interested in experimenting with the Blockchain technology for a while, and this was a great opportunity to do so. It took reading lots of articles and a few hours of work, but I did have some success! (Or rather, proof-of-concept success ;-)
I thought it might be interesting if I share my journey with you in turning a data analytics machine into a Bitcoin mining machine. I was quite surprised by the results. and I bet you will be, too!
But first things first: let’s do a super-quick overview of how Bitcoin mining works.
Mining Bitcoins in a Nutshell
You have probably heard that mining Bitcoin involves solving a computationally hard mathematical problem, and this is true: the Bitcoin system consists of transactions (that is, transferring money between users), and these transactions are registered in a public ledger, called the blockchain. The blockchain, as the name suggests, is a linked-list of blocks of transaction data.
Mining Bitcoin essentially involves finding a valid next block, which in turn, gives you, the miner, a prize — currently, 12.5BTC for every block you find.
Each block comprises of two parts: an 80-byte header, followed by a list of transactions. The header includes the identifier of the previous block (i.e., the hash of the previous block’s header), as well as an SHA256 hash of the list of transactions as well as some other information. As a miner, you basically have to somehow make sure that the block’s header, when hashed twice using the SHA256 hash function, is smaller than a given number, also referred to as the “difficulty” — or how hard it is to find the target number (i.e., the valid next block).
Bitcoin blocks are mined at a rate of about 1 block in every 10 minutes. In order to ensure the rate stays constant, the difficulty is automatically adjusted every 2016 blocks (roughly every two weeks), so it is more or less proportional to the total computing power miners put into the process.
Mining basically involves trying different variations for the header, mainly in the nonce field (the last 4 bytes of the header) until you eventually find a header whose hash starts with a given number of zeros (or, to put it differently — smaller than some number, as I stated before).
If you want a more detailed explanation, you can check out Ken Shirriff’s blog post about Bitcoin mining, or simply follow along and collect the pieces of information I mention throughout the post.
Mining with BigQuery
You are invited to follow my footsteps and run the examples in this blog. Some of the queries presented here may resemble parts of the Bitcoin mining process. If you have a Google Cloud Platform Free trial account, their terms prohibit you from engaging in mining cryptocurrency. While none of the examples presented in this post will actually mine any cryptocurrency, I still advise you to play it safe and have a paid Google Cloud Platform account, which, to best of my knowledge, does not prohibit mining cryptocurrencies in any way.
First Things First: Looking at a Block’s Header
Let’s start by looking how mining is done in practice. We will take a look at the header of some block from the Bitcoin blockchain and try to calculate the hash ourselves to see how it’s done (and then also verify we can do the hashing part with BigQuery).
But where do we find a block?
Turns out, you can find the entire Blockchain in BigQuery. But for our purposes, we are going to do use a different source, which also provides a way for us to get the raw binary data of the block: a website called blockchain.info. I randomly picked one of the recent blocks, number 514868:
You can get the binary data for this block (hex encoded), by clicking on the block’s hash, and then appending ?format=hex to the URL, resulting in this link. The block view also shows the complete list of transactions and other interesting data, and I invite you to explore on your own.
For now, though, let’s keep focused on the header. We’ll copy the first 160 characters from the block’s data (that’d be the first 80 bytes):
000000204a4ef98461ee26898076e6a2cfc7c764d02b5f8d670832000000000000000000f99f5c4d5025979fcb33d245536a55b628d4564c075c0210cbbc941ad79fdbc5e491b55a494a5117ac997500This Bitcoin Wiki page explains how the hashing algorithm works: we basically need to take this header and run the SHA256 function on it, then run it again on the result of the first run. This should result in the hash of the block.
So first thing, if we wanted to do this in BigQuery, we would need a SHA256 function. Luckily, it was introduced in version 2 of BigQuery (a.k.a. Standard SQ). We also need some method of converting these hex values into actual bytes. Luckily, a function called FROM_HEX got us covered. So far so good.
Now we can try writing the actual query (as a single line):
SELECT TO_HEX(SHA256(SHA256(FROM_HEX(
'000000204a4ef98461ee26898076e6a2cfc7c764d02b5f8d670832000000000000000000f99f5c4d5025979fcb33d245536a55b628d4564c075c0210cbbc941ad79fdbc5e491b55a494a5117ac997500'))))(If you want to follow along, you can try to run this query on the BigQuery console. You will also need to uncheck the “Use Legacy SQL” query options. If you get an error that reads: “Unrecognized function to_hex”, it means you didn’t uncheck this box.)
By running the above query, we get the following result:
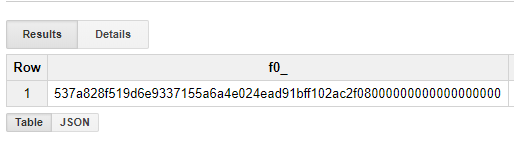
When I did this the first time, I was quite disappointed , because it seemed like the hash was different from the original hash of the block. I quickly realized, however, that it was just reversed! (Apparently, Bitcoin hashes are stored little-endian).
Adding a REVERSE function just before calling TO_HEX did the trick:
SELECT TO_HEX(REVERSE(SHA256(SHA256(FROM_HEX(
'000000204a4ef98461ee26898076e6a2cfc7c764d02b5f8d670832000000000000000000f99f5c4d5025979fcb33d245536a55b628d4564c075c0210cbbc941ad79fdbc5e491b55a494a5117ac997500')))))
So, that’s quite an achievement already: we now know that we can verify the hashes for Bitcoin blocks on BigQuery. If we wanted to use BigQuery to mine, we’d want use the same set of functions, except we wouldn’t have the complete header: we would have to search for a valid header with a small enough hash value.
A valid header consists of 6 fields:
version— Values of 2, 3, and 4 are common (new values are being added)hashPrevBlock— The hash of the previous block in the chainhashMerkleRoot— Hash of all the transactions in the block (explainer)time— Timestamp of when the block was createddifficulty— The difficulty of the block stored as a floating point numbernonce— 4 bytes that we can vary to affect the header value
Mining is basically trying all the possible combinations for nonce, and then checking the hash for each until the hash is below the target value. The target value can be easily derived from the block’s difficulty:
target = (0xffff * 2**(256-48)) / difficultyThe minimum difficulty for any block is 1. Therefore, any target is going to have at least 48 leading zeros. So, as the difficulty number for our block was 3462542391191.563, the target was: 000000000000000000514a490000000000000000000000000000000000000000
You can find the current difficulty and target value here (the link will also give you a little more explanation about the relationship between the difficulty and the target value).
So, basically, if we wanted to reproduce the mining process for this block, we’d just have to try all the different combinations for the nonce, the last 4 bytes of the header, until we found one whose hash is smaller than the above number.
Re-Mining the Block
I decided to start small by just searching for the last byte, as we already have the answer in this case. Initially I thought about uploading a small table with all the numbers between 0 and 255 (the valid values for that byte), but then I found that this table can actually be mimicked by combining two SQL functions: UNNEST() and GENERATE_ARRAY() :
SELECT * FROM UNNEST(GENERATE_ARRAY(0, 255)) num;Armed with this knowledge, I created my first query that tried to reproduce the mining process inside BigQuery:
SELECT
TO_HEX(CODE_POINTS_TO_BYTES([0xac, 0x99, 0x75, num])) AS nonce
FROM
UNNEST(GENERATE_ARRAY(0, 255)) num
WHERE
TO_HEX(REVERSE(SHA256(SHA256(CONCAT(FROM_HEX(
'000000204a4ef98461ee26898076e6a2cfc7c764d02b5f8d670832000000000000000000f99f5c4d5025979fcb33d245536a55b628d4564c075c0210cbbc941ad79fdbc5e491b55a494a5117'), CODE_POINTS_TO_BYTES([0xac, 0x99, 0x75, num]) ))))) LIKE '000000000000000000%'Okay, let’s tease that out a little!
Basically, since we’re only searching for correct the nonce, I removed that part from the header (you can check — the long hex string in the query is only 152 characters long, which represents 76 bytes, that is, the header without the nonce). What our query is looking for is a 4 byte value that, once appended to the header, will result in an hash smaller than the target number.
Since this was my initial trial, I used the values I already know from the block for the first 3 bytes in the nonce, and only had BigQuery search for the final byte. This worked like a charm, and it quickly found the correct nonce value:
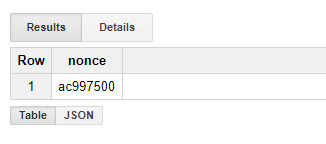
You might be wondering why I used LIKE inside the WHERE clause to filter the correct result. I do this because we are simply looking for hashes smaller than the target value. As the target value start with 18 zeros, we simply filter out any number that doesn’t start with 18 zeros (as it’s obviously bigger than the target value). This means that we may get some false positives (e.g. number that starts with 18 zeros and then any digit larger than 5), but we can quickly filter them out manually.
So now, when we know how to search for the sneaky nonce, we can quickly expand the search to more bytes:
SELECT
TO_HEX(CODE_POINTS_TO_BYTES([0xac, num2, num3, num4])) AS nonce
FROM
UNNEST(GENERATE_ARRAY(0, 255)) num2,
UNNEST(GENERATE_ARRAY(0, 255)) num3,
UNNEST(GENERATE_ARRAY(0, 255)) num4
WHERE
TO_HEX(REVERSE(SHA256(SHA256(CONCAT(FROM_HEX(
'000000204a4ef98461ee26898076e6a2cfc7c764d02b5f8d670832000000000000000000f99f5c4d5025979fcb33d245536a55b628d4564c075c0210cbbc941ad79fdbc5e491b55a494a5117'), CODE_POINTS_TO_BYTES([0xac, num2, num3, num4]) ))))) LIKE '000000000000000000%'While this query does the trick and finds the 3 bytes, there was one problem: it runs slow! This query took about 30 seconds to complete. If we were to search for all the 4 bytes, it’d take about two hours at this speed. I mentioned above that a new block is mined every 10 minutes, so by the time we found a result, we’d already be behind and it would not be relevant.
This was a little disappointing (what happened to BigQuery’s “highly scalable” promise?), so I decided to explore further and try to see if I could do anything to improve this.
From my previous BigQuery experience, I remembered that joining different tables was an expensive operation that caused queries to run for much longer. I tried to remove the joining step by generating a larger table (i.e., telling GENERATE_ARRAY to generate more numbers), but after some trial and error, it seemed like the maximum size of table would still be around 1 million rows, which means I’d still have to join tables or only search for 1 millions hashes every time (which is kind of pointless, as my computer’s CPU can do this in less than a second).
So it seemed like it would be possible to mine Bitcoin with BigQuery, but hardly practical.
Still, I’m not too fond of giving up, so I tried a few more approaches. And one of them actually worked!
Mining Faster
I recalled that BigQuery had some very large public data sets containing enormous tables. After scanning a few of them, I found one that contained 5.3 billion rows, which is just above 4,294,967,296, the number of the different number of combinations for nonce. If I could construct a query that would go over this table and try a different combination for each row in the table, I’d be able to cover all the possible combinations.
I tried to use the ROW_NUMBER() OVER() SQL function for this, which should return the current row number (then I could derive a different set of bytes for each row, according to the row number), but it quickly died with the following error:
Resources exceeded during query execution: The query could not be executed in the allotted memory..
Bummer! But then, I started thinking — what if I just tried random numbers? eventually, there is a very good chance that if there is a matching hash, I will find it, as the number of tries is greater than the number of combinations.
So, I came up with this query:
SELECT TO_HEX(nonce)
FROM (
SELECT
CODE_POINTS_TO_BYTES([
CAST(TRUNC(256*RAND()) AS INT64),
CAST(TRUNC(256*RAND()) AS INT64),
CAST(TRUNC(256*RAND()) AS INT64),
CAST(TRUNC(256*RAND()) AS INT64)
]) AS nonce
FROM
`fh-bigquery.wikipedia.wikipedia_views_201308`
)
WHERE
TO_HEX(REVERSE(SHA256(SHA256(CONCAT(FROM_HEX(
'000000204a4ef98461ee26898076e6a2cfc7c764d02b5f8d670832000000000000000000f99f5c4d5025979fcb33d245536a55b628d4564c075c0210cbbc941ad79fdbc5e491b55a494a5117'), nonce ))))) LIKE '000000000000000000%'CAST(TRUNC(256*RAND()) AS INT64) generates a random number between 0 and 255, and then the inner SELECT part simply generates a table with ~5.3 billion rows of four random values. Then the outer query makes sure we only get values which actually result in a low enough hash — which is what we are looking for!
To my pleasant surprise, this query returned in mere 20.9 seconds — and it indeed found the correct nonce value (it even found it twice!):
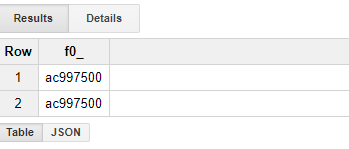
This means that I was able to check nearly 4 billion hashes in 20 seconds, or about 200 mega-hashes per second. That’s not too bad — considering GPUs will only get you about 30–60 mega-hashes/second (CPUs even less, not to mention mining with pencil and paper).
So, obviously, this gets us nowhere near a dedicated mining hardware speed-wise, but there was still one more trick I had under my sleeve…
Concurrency
If you are a sharpshooter in combinatorics, you might have noticed that checking all the possible values for nonce doesn’t guarantee a very good chance of finding a small enough hash (like I said at the beginning, it’s a hard problem!).
At time of writing, the target was roughly 2¹⁸² (see how we calculate the target from difficulty above), which means there are 2¹⁸² valid hash combinations out of 2²⁵⁶ total possible, or in other words — the chance for an arbitrary hash to be lower than the target is 1 in 2⁷⁴.
This basically means that if we only vary nonce, we will check 2³² possibilities, and our chance to actually find a desired hash is super small: so we need more bytes to play with.
If we take another look at the header structure, you will notice that we can slightly change the time field (other nodes will still accept the block if the time is slightly off), or we can change something in the list of our block’s transactions, which will result in a completely different value for the merkle root hash field.
One way of varying the transaction list (and thus generating a different merkle hash) is by adding an extra payload to the first transaction, called the extraNonce, which can have up to 100 bytes. Another way would just be to pick a different set of transaction to be included in the block.
The point is, in order to be a successful miner, one has to try different combinations of transaction list and/or vary the time field, in addition to the nonce. This means that we can run the query that we found multiple times, in parallel, each time with a different block header. But how many concurrent queries does BigQuery allow?
According to the quotas page, you can read up to 50 concurrent queries, which can, theoretically, result in up to 50 times faster hashing. Does it really work? I do not know, I haven’t tried. Currently, my best result with a single query was 500 Mega-hashes per seconds (using this 106-billion row wikipedia dataset as a source table), which means with a limit of 50 concurrent queries, we can theoretically get up to 25 Giga-hashes/second. Like a moderate dedicated mining hardware — which isn’t too bad, considering it’s essentially free.
So, how much does it cost?
BigQuery claims to be a cost-effective solution. By now I was already convinced with their scalability claim, but their pricing structure was a surprise to me, too. A very good surprise.
The pricing model for BigQuery is solely based on the amount of data you query: you are basically billed by the byte. The thing is, you are not billing for the processing power or any intermediate data that your query generated — just for bytes you read from the source table.
In our case, we use enormous source tables, but we just use them to generate a large number of random number combinations — we don’t actually read any data for the tables. BigQuery has a nice feature where it shows the estimated price for a query (as the number of bytes you will be billed for). The first 1 Terabyte is free every month, and you pay 5$ for every additional Tetabyte you query after that. Not bad!
So, if we check what BigQuery estimates for our big query, this is what we find:
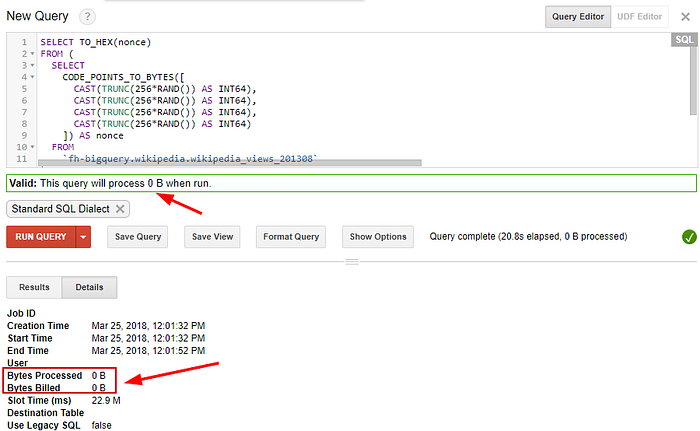
So basically, we can run as many such queries as we want, for free! They surely measure up to their cost-effectiveness claim (in this case, at least).
Summary and Conclusions
This started as a fun exercise, with purpose of learning better how the blockchain works. When I started, I was pretty sure I would hit some hard limit (perhaps some CPU time quota or something), and I must say I am still pretty surprised that I could get all this computation power for free.
While my research shows that it should be possible to turn BigQuery into a mining machine in theory, there is still a considerable amount of work that would have to be done if I wanted to automate the mining process. A crude calculation shows that even if such a miner was built, when competing with all the dedicated mining hardware running around the world, it would make me roughly $5 a year. Nevertheless, now I know that Bitcoin can be mined with SQL, which is priceless ;-)
But most importantly, this experiment gave me a whole new perspective about the enormous computing power that is being spent mining Bitcoin. We’re talking about 26 billion giga-hashes per second — that is 2.6*10¹⁹ , which is more than the number of grains of sand on earth. Every second. You’ve got to wonder what we’d achieve if we used even a fraction of this computing power for medical research instead…
